We all are familiar with Relational and Document data model and databases which rely upon these model to give a logical structure to our data.
But there are few more data model that is worth pondering upon.
Graph-Like Data Models are not so popular among mass but power many data systems like Recommendation systems and is the need of the hour for emerging fields like Data Science, Analytics and Artificial Intelligence for scalable solutions.
The need...
Anyone who has worked with Relational databases knows that the data is organized in what is called as relations, where each relation is an unordered collection of tuples.
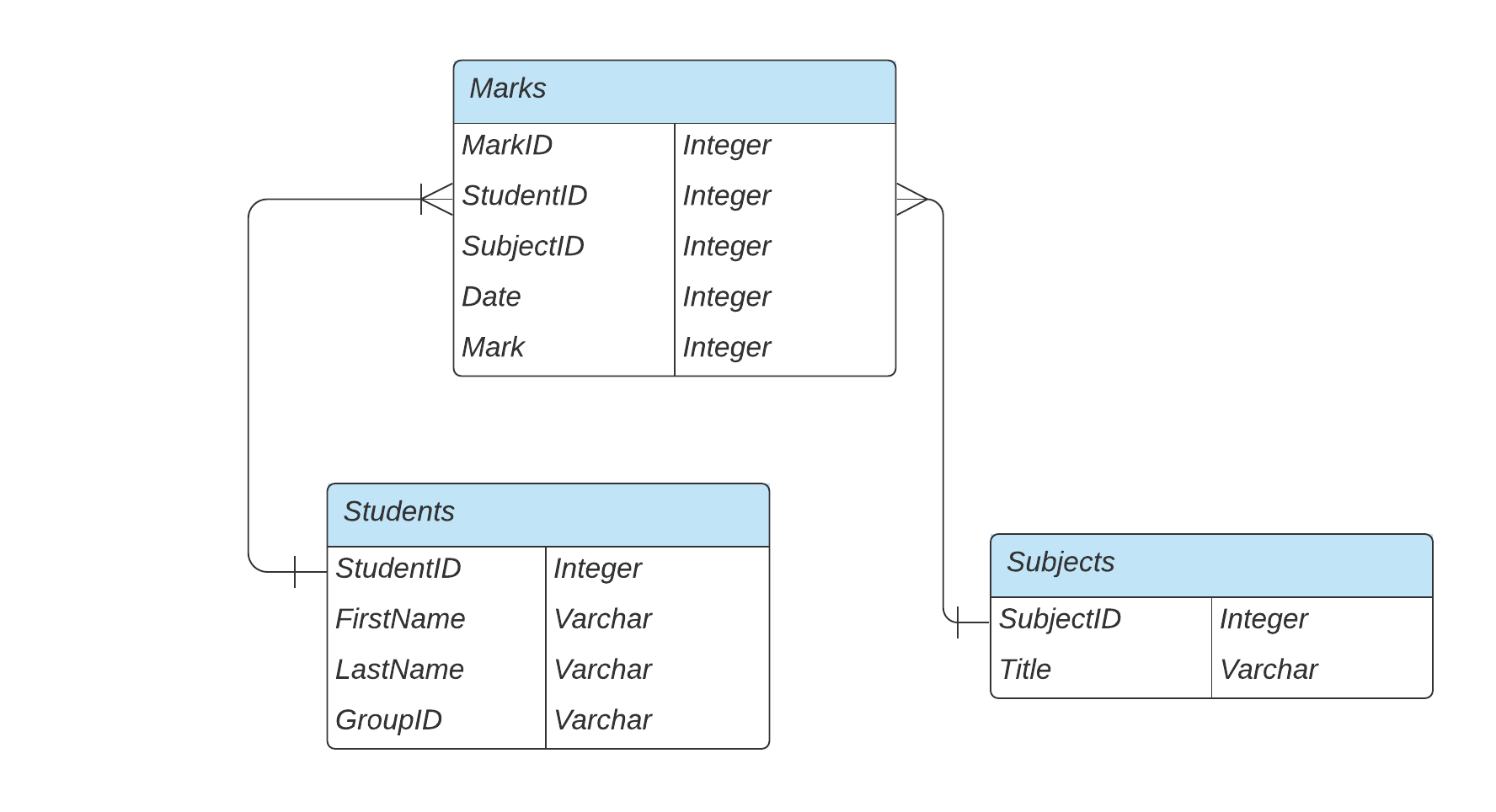
Relational data model is good for most use cases preferably where there is some kind of regular structure to data and few many-to-one or one-to-many relationship.
When application has mostly one-to-many relationships (tree-structured/document-like structure where typically the entire tree needs to be loaded at once) or no relationships between records, the document model becomes the choice. Names like MongoDB starts coming into play.
It starts to tumble down when our data has just too many many-to-many relationships.
The joins operations in relational data model would make it just too difficult to query and no wonder other limitations by enforcing a schema. The document model lacks support for joins altogether and instead focuses on locality.
A graph consist of two kinds of objects: vertices (nodes or entities) and edges (relationships or arcs). The data usually modeled as graph are from social networks, the web network of pages and many more.
There are several different ways of structuring and querying graph data. We'll look at two graph model commonly implemented by graph databases.
- Property Graph model
- Triple-store model
Property Graph model
In a property graph model, each vertex consists of
- A unique identifier
- A set of outgoing edges
- A set of incoming edges
- A collection of properties (key-value pairs)
Each edge consist of:
- A unique identifier
- The vertex at which the edge starts (the tail vertex)
- The vertex at which the edge ends (the head vertex)
- A label to describe the kind of relationship between the two vertices
- A collection of properties (key-value pairs)
Trying to represent this model in a relational model is easy but you won't have to do this in an actual database.
CREATE TABLE vertices (
vertex_id integer PRIMARY KEY,
properties json
);
CREATE TABLE edges (
edge_id integer PRIMARY KEY,
tail_vertex integer REFERENCES vertices (vertex_id),
head_vertex integer REFRENCES vertices (vertex_id),
label text,
properties json
);
CREATE INDEX edges_tails ON edges (tail_vertex);
CREATE INDEX edges_heads ON edges (head_vertex);This gives us certain useful features such as:
- Any vertex can have an edge connecting it with any other vertex.
- Given a vertex, we can easily and efficiently find both its incoming and its outgoing edges.
- By using different labels for different kinds of relationships, we can store several different kinds of information.
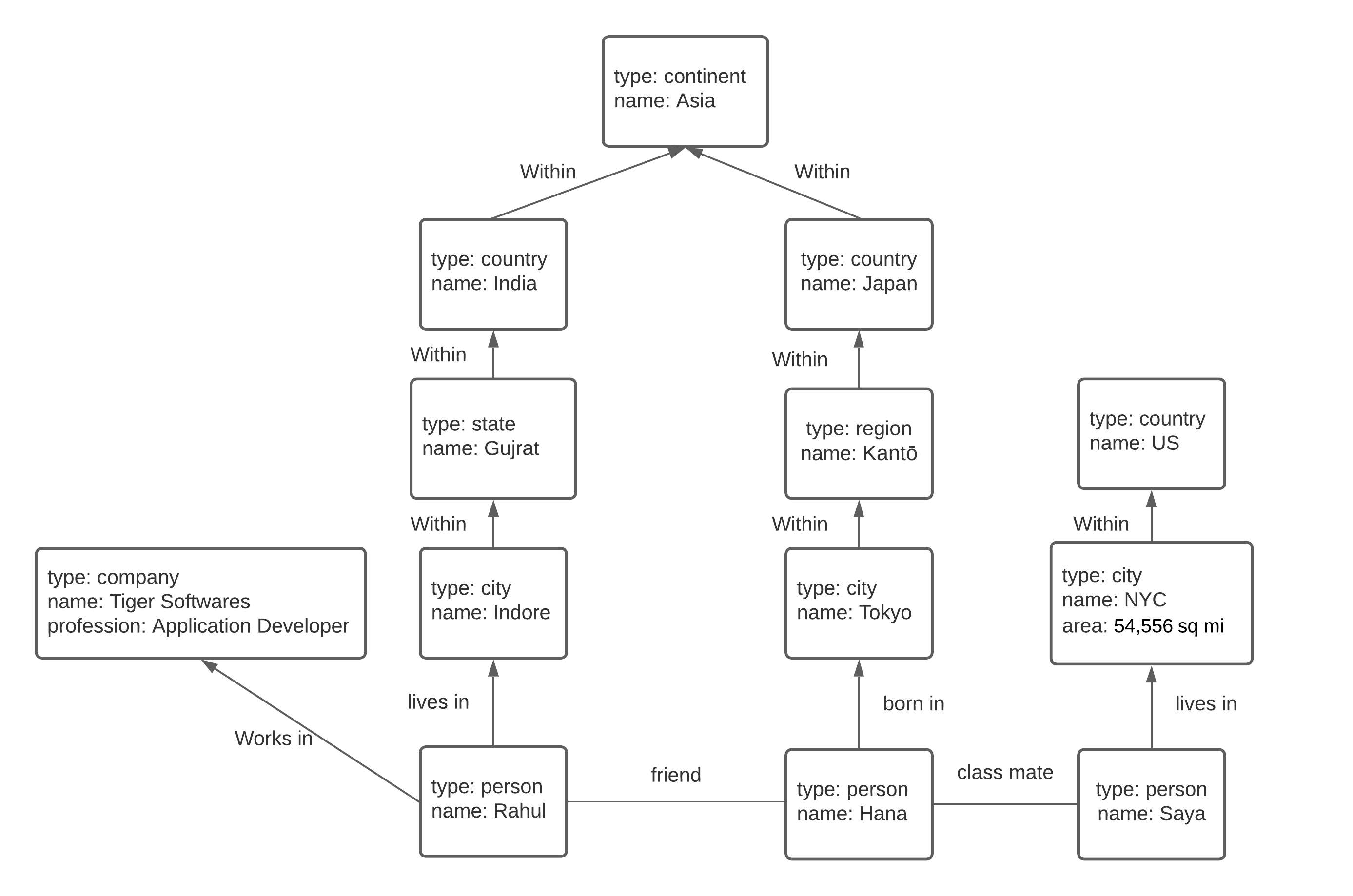
- Flexible enough to store multitude of similar information (notice in the graph figure above; Hana lives in region Kantō, and Rahul lives in state Gujrat. Rahul's profession is Application Developer).
Databases implementing this data model are Neo4j, Titan, and InfiniteGraph.
Cypher Query Language
Cypher is a graph query language developed to query property graphs originally intended to be used with graph database Neo4j.
Each vertex is given a symbolic name like Indore or NYC denoted with brackets (), and other parts of the query can use these names to create edges between the vertices, using an arrow notation with square brackets [:<relationship>]representing the relationship (refer the graph structured data above):
(Indore) -[:WITHIN]-> (Gujrat) -[:WITHIN]-> (India)
We can write the data in cypher query like this:
CREATE
(India:Location {name: 'India', type: 'country'}),
(Gujrat:Location {name: 'Gujrat', type: 'state'}),
(Indore:Location {name: 'Indore', type: 'city'}),
(Rahul:Person {name: 'Rahul'}),
(TS:Company {name: 'Tiger Softwares', profession: 'Application Developer'}
(Rahul) -[:WITHIN]-> (Indore) -[:WITHIN]-> (Gujrat) -[:WITHIN]-> (India)
(Rahul) -[:WORKS_IN]-> (TS)To query the data from this graph is also easy, we use the same arrow notation in a MATCH clause to find patterns in the graph.
Let's find all the persons who lives in the state Gujrat, works in Tiger Softwares (assume we have added all the data).
MATCH
(person) -[:WORKS_IN]-> (TS:Company {name: 'Tiger Softwares'}),
(person) -[:LIVES_IN]-> () -> [:WITHIN*0..]-> (Gujrat:Location {name:'Gujrat'})
RETURN person.nameThe query can be interpreted as follows:
Find any vertex (call it person) that meets both of the following conditions:
personhas an outgoingWORKS_INedge to some vertex (call itTS) of typeCompanywhich has the itsnameproperty set to "Tiger Softwares".- That same
personalso has outgoingLIVES_INedge to some vertex, following the chain from that vertex with outgoingWITHINedge, get to a vertex of typeLocationwhosenameproperty has been set to "Gujrat".
For each such person, return its name property.
Triple-Stores or RDF store
Triple-store model is another graph model quite similar to property graph model but with simpler ideas.
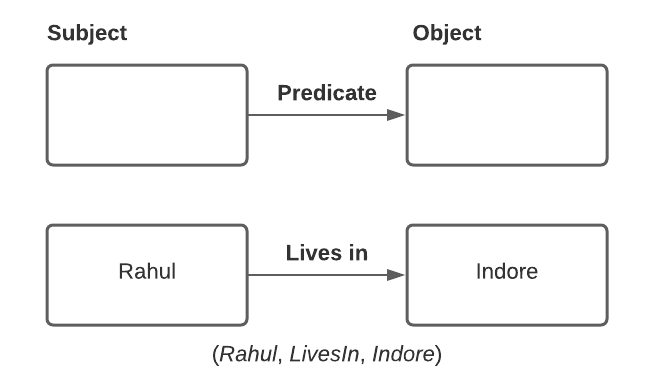
In triple-store, the information is stored in the form of very simple three-part statements: (subject, predicate, object). For example, in the triple (I, want, apple), I is the subject, want is the predicate (verb), and apple is the object.
The subject of a triple is equivalent to a vertex in a graph.
The object is one of two things:
- A value in a primitive datatype. In that case the predicate and object forms the key-value pair of a property on the subject vertex.
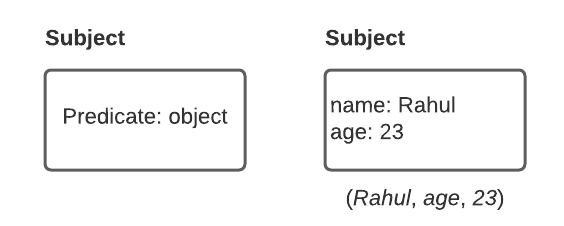
- Another vertex in the graph. In that case the predicate is an edge label with head vertex being the object and tail vertex becoming the subject.
The graph data can be written (and imported and exported) as Turtle triples, Tutle which stands for Terse RDF Triple Language, is a syntax and file format for expressing data in the Resource Description Format (RDF).
The vertices are represented as _:someName. This name only exist to know which triple refer to the same vertex. The predicates then starts with : following the object.
@prefix : <urn:example:>
_:india a :Location; :name "India"; type: "country".
_:gujrat a :Location; :name "Gujrat"; type: "state"; :within _:india.
_:indore a :Location; :name "Indore"; type: "city"; :within _:gujrat.
_:ts a :Company; :name "Tiger Softwares"; :profession "Application Developer".
_:rahul a :Person; :name "Rahul"; :worksIn _:ts.When the predicate is a property, the object is a string literal, as in :name "India"
When the predicate is an edge, the object is a vertex, as in :worksIn _:ts.
This model is implemented by Datomic, AllergoGraph, and others.
The SPARQL query language
SPARQL (pronounced "sparkle") which stands for SPARQL Protocol and RDF Query Language is a query language for triple-stores using the RDF data model.
The same query as before – finding people who who lives in the state Gujrat, works in Tiger Softwares– can be written as follows in SPARQL:
The key thing to note is variables start with a question mark in SPARQL.
PREFIX : <urn:example:>
SELECT ?personName where {
?person :name ?personName.
?person :livesIn / :within* / :name "Gujrat".
?person :worksIn / :within* / :name "Tiger Softwares".
}That's it for today. I hope you learned something new.
Keep Learning...