Yeah, not every ML model trains in minutes, at least not in Deep Learning space.
The more complex the model is, the larger the dataset is required to train it because the subsequent increase in parameters. This leads to taking longer to fit a batch, and hence longer training time.
In that case, it is good to think about measures to withstand the chances of machine failure during the training process. We don't want to begin from scratch when we have already done half of the work.
Checkpoints allow us to store the full state of the partially trained model (the architecture, weights) along with hyerparameters/parameters required to begin training from that point, periodically during the training process.
We can use this partially trained model as:
- Final models (in case of early stoping, discussed later)
- Starting point to continue training (machine failure and fine-tuning)
Checkpoints make sure to save the intermediate model state, as compared to exporting in which only the final model parameters (weights & biases) and architecture are exported. To begin retraining more information is required other than the above two. Take, for example, the optimizer that was used, with what parameters it was running, its state, how many epochs were set, how many were completed, and so on.
In Keras, we can create checkpoints using Keras callback, ModelCheckpoint passed to fit() method.
import time
model_name = "my_model"
run_id = time.strftime(f"{model_name}-run_%d_%m_%Y-%H_%M_%S")
checkpoint_path = f"./checkpoint/{run_id}.h5"
cp_callback = tf.keras.callbacks.ModelCheckpoint(
checkpoint_path,
save_weights_only=False,
verbose=1)
history = model.fit(
x_train, y_train,
batch_size=64,
epochs=3,
validation_data=(x_val, y_val),
verbose=2,
callbacks=[cp_callback])ModelCheckpoint allow us to save checkpoints after the end of each epoch. We can do checkpointing at the end of each batch, but the checkpoints size and I/O will add too much overhead.
Why it works
Partially trained models offer more options than just continued training. This is because they are usually more generalizable than the models created in later iterations.
We can break the training into three phases:
- In the first phase, training focuses on learning high-level organization of data.
- In the second phase, the focus shifts to learning the details.
- Finally in the third phase, the model begins overfitting.
A partially trained model from the end of phase 1 or from phase 2 becomes more advantageous because it has learned the high-level organization but still hasn't dived into the details.
Trade-Offs and Alternatives
Early Stopping
Usually, the longer the training continues, the lower the loss goes on the training dataset. However, at some point, the rror on the validation dataset might stop decreasing. This is where overfitting begins to take place. This phenomenon is evident with the increase in the validation error.
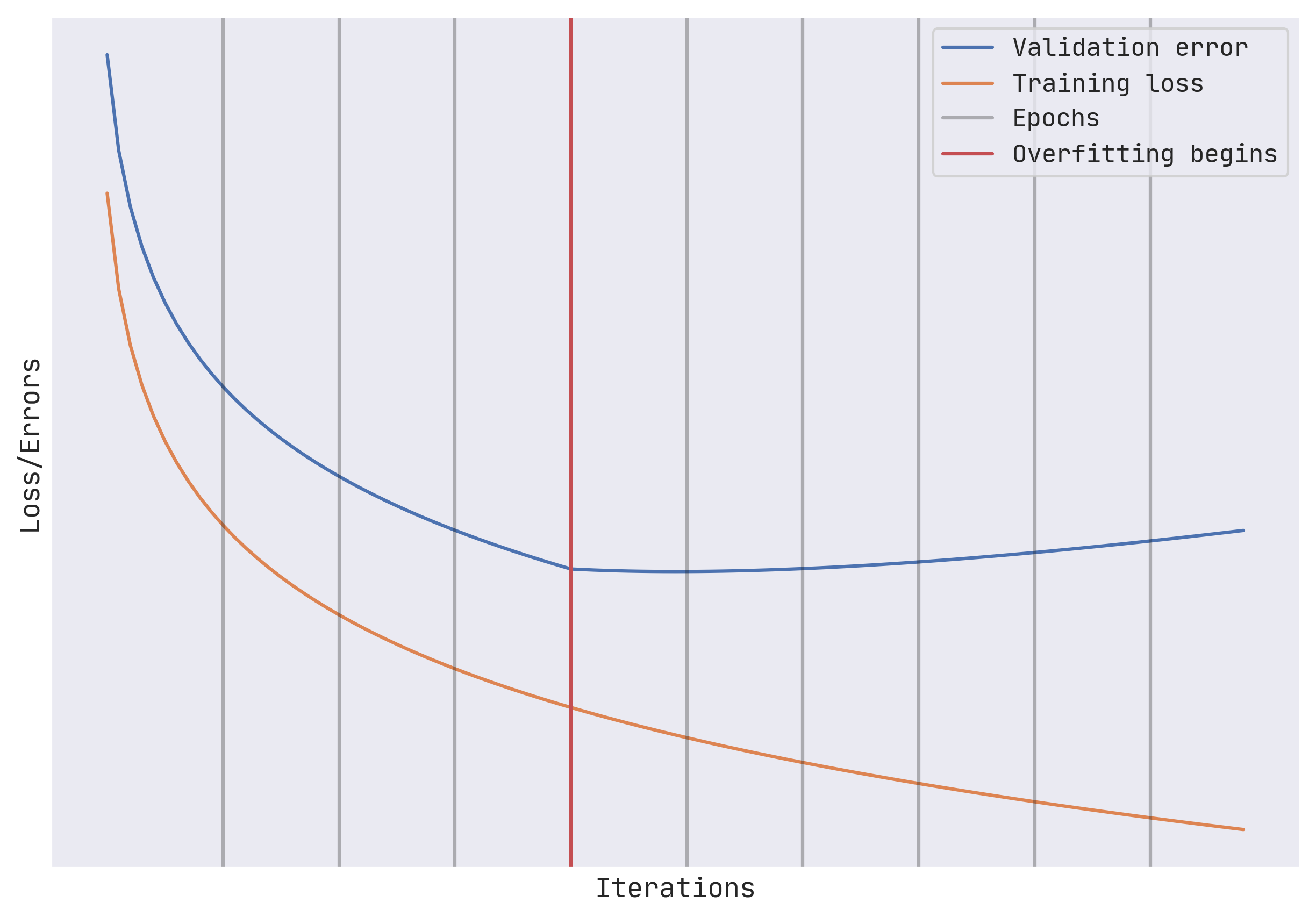
It can be helpful to look at the validation error at the end of every epoch and stop training when the validation error is more than that of the previous epoch.
Checkpoint selection
It is not uncommon for the validation error to increase for a bit and then start to drop again. This usually happens because training initially focuses on more common scenarios (phase 1), then on rare samples (phase 2). Because rare situations may be imperfectly sampled between the training and validation datasets, occasional increases in the validation error during the training run are to be expected in phase 2.
So, we should train for longer and choose the optimal run as a preprocessing step.
In our above example, we'll continue training for longer. Load the fourth checkpoint and export the final model. This is called checkpoint selection and in TensorFlow can be achieved using BestExporter.
Regularizations
We can try to plateau both, validation error and training loss by adding L2 regularization to the model instead of the above two techniques.
Such a training loop is termed as a well-behaved training loop.
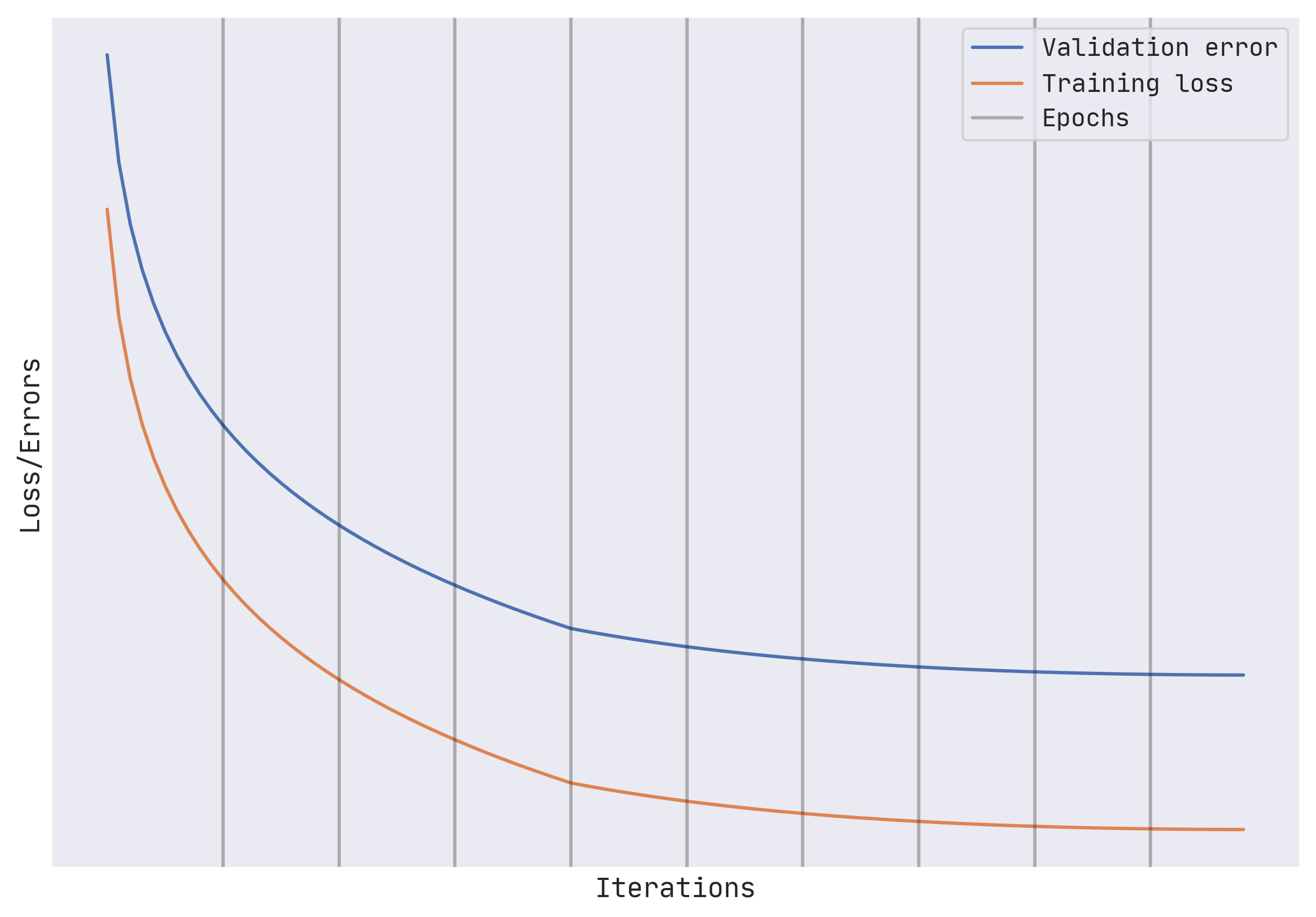
However, recent studies suggest that double descent happens in a variety of machine learning problems, and therefore it is better to train longer rather than risk a suboptimal solution by stopping early.
In the experimentation phase (when we are exploring different model architectures, hypertuning, etc), it's recommended that you turn off early stopping and train with larger models. This will ensure that model has enough capacity to learn the predictive patterns. At the end of experimentation, you can use the evaluation dataset to diagnose how well your model does on data it has not encountered during training.
When training the model to deploy in production, turn on early stopping or checkpoint selection and monitor the error metric on the evaluation dataset.
When you need to control cost, choose early stopping, and when you want to prioritize model accuracy choose checkpoint selection.
Fine-tuning
Fine-tuning is a process that takes a model that has already been trained for one given task and then tunes or tweaks the model to make it perform a second similar task. Since our checkpoint model, we can train on an already optimally performing model on small fresh data.
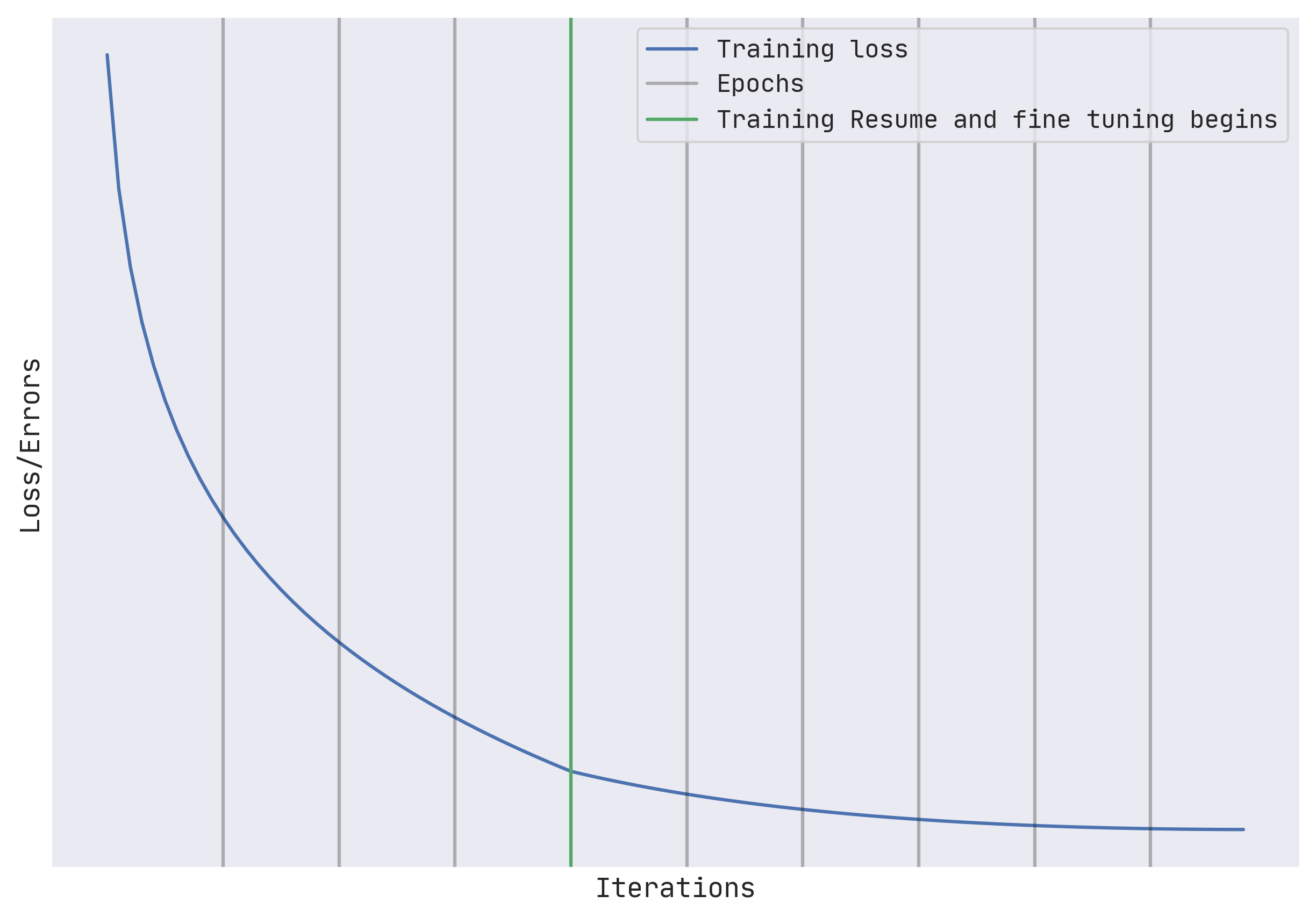
Starting from an earlier checkpoint tends to provide better generalizations as compared to final models/checkpoints.
Redefining an epoch
Epochs are easy to understand. It is number of times the model has gone over the entire dataset during training. But the use of epochs can leads to bad effects in real-world ML models.
Let's take an example, were we are going to train a ml model for 15 epochs using a TensorFlow Dataset with one million examples.
cp_callback = tf.keras.callbacks.ModelCheckpoint(...)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
batch_size=128,
callbacks=[cp_callback])The problem with this are:
- If the model converges after having seen 14.3 million examples (i.e., after 14.3 epoch) we might want to exit and not waste any more computational resource.
ModelCheckpointcreates checkpoint at each epoch end. For resilience, we might want to checkpoint more often instead of waiting to process 1 million examples.- Datasets grows over time. If we get 1,00,000 more examples and we train the model and get a higher error, is it because we need an early stop or the data is corrupt. We can't tell because the prior training was on 15 million examples and the new one is on 16.5 million examples (15 million + 1,00,000 new examples * 15 epochs).
- In distributed, parameter-server training the concept of an epoch is not clear. Because of potentially straggling workers, you can only instruct the system to train on some number of mini-batches.
Steps per epoch
Instead of training for 15 epochs, we might decide to train for 143,000 steps where batch_size is 100:
NUM_STEPS = 143_000
BATCH_SIZE = 100
NUM_CHECKPOINTS = 15
cp_callback = tf.keras.callbacks.ModelCheckpoint(...)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=NUM_CHECKPOINTS,
steps_per_epoch=NUM_STEPS // NUM_CHECKPOINTS,
batch_size=BATCH_SIZE,
callbacks=[cp_callback])It works as long as we make sure to repeat the train_ds infinitely:
train_ds = train_ds.repeat()Although this gives us much more granularity, but we have to define an "epoch" as 1/15th of the total number of steps:
steps_per_epoch=NUM_STEPS // NUM_CHECKPOINTSRetraining with more data
Let's talk about the scenario when we added 1,00,000 more examples. Our code remains same and processes 143,000 steps except that 10% of the examples it sees are newer.
If the model converges, great. If it doesn't we know that these new data points are the issue because we are not training as we were before.
Once we have trained for 143,000 steps, we restart the training and run it a bit longer. as long as model continues to converge. Then, we update the number 143,000 in the code above (in reality, it will be a parameter to the code) to reflect the new number of steps.
This works fine until you begin hyperparameter tuning. Let's say you changes the batch size to 50, then you'll only be training for half the time because the steps are constant (143,000) and each step is now will only take half as long as before.
Introducing Virtual epochs
The solution is to keep the total number of training examples shown to the model constant and not the number of steps.
NUM_TRAINING_EXAMPLES = 1000 * 1000
STOP_POINT = 14.3
TOTAL_TRAINING_EXAMPLES = int(STOP_POINT * NUM_TRAINING_EXAMPLES)
BATCH_SIZE = 100
NUM_CHECKPOINTS = 15
steps_per_epoch = (
TOTAL_TRAINING_EXAMPLES // (BATCH_SIZE * NUM_CHECKPOINTS)
)
cp_callback = tf.keras.callbacks.ModelCheckpoint(...)
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=NUM_CHECKPOINTS,
steps_per_epoch=steps_per_epoch,
batch_size=BATCH_SIZE,
callbacks=[cp_callback]
)When we get more data, first train it with the old settings, then increase the number of examples to reflect the new data, and finally change the STOP_POINT to reflect the number of times you have to traverse the data to attain convergence.
This will work even when we are doing hyperparameter tuning while retaining all the advantages of keeping the number of steps constant.
Hope you learned something wonderful.
This is Anurag Dhadse, Signing off.





