Wisdom of crowd.
Wisdom of crowds is a theory that assumes that the knowledge or collective opinion of a diverse independent group of individuals results in better decision-making, innovation, and problem-solving than that of an individual.
In the machine learning space, when it's harder to build a model that has a substantially lower reducible error, instead of building for larger models, we can combine several diverse ml models.
But what reducible error we are talking about?
You see, the error of an ML model can be broken down into two parts:
$$\text{Error of model} = \text{Irreducible error} + \text{Reducible error}$$
The irreducible error is the inherent error in the model resulting from noise in the dataset, bad training examples, or framing of the problem.
And the reducible error is made up of:
$$\text{reducible error} = \text{Bias}\space \text{\textbf{Or}}\space \text{Variance}$$
The bias is the model's inability to learn enough about the relationships between the model's features and labels. This is due to wrong assumptions such as the data is linearly separable when it is actually quadratic.
The variance captures the model's inability to generalize on new, unseen examples due to model's excessive sensitivity to small variations in the training data.
A model with high bias oversimplifies the relationship and becomes underfit, and a model with high variance learns too much (kind of cram everything) and is said to overfit.
Our task in modeling is to lower both bias and variance, but in practice, however, this is not possible. This is called as bias-variance trade-off.
Ensemble is a solution for this trade-off applied to small and medium-scale problems to reduce the bias and/or variance to help improve performance. This involves as stated above to combine multiple models and aggregating their outputs to generate the final result.
The most common techniques in Ensemble Learning are:
- Bagging–good for decreasing variance
- Boosting–good for decreasing bias
- Stacking
Bagging
Bagging or bootstrap aggregating is a type of parallel ensembling method where the same training algorithm for every predictor and train them on different random subsets of training set with replacement.
When sampling is performed without replacement, it is called pasting.
Then aggregation is performed on the output of these models–either an average or majority vote in the case of classification.
This works because each individual model can be off by a random amount, so when their results are averaged, these errors cancel out.
We can also have hard-voting or soft voting when performing aggregation for classification models:
- If the majority-vote classifier output is selected, then it is hard voting.
- If the highest class probability from all classifiers are averaged for final selection of classification output, then it is soft voting.
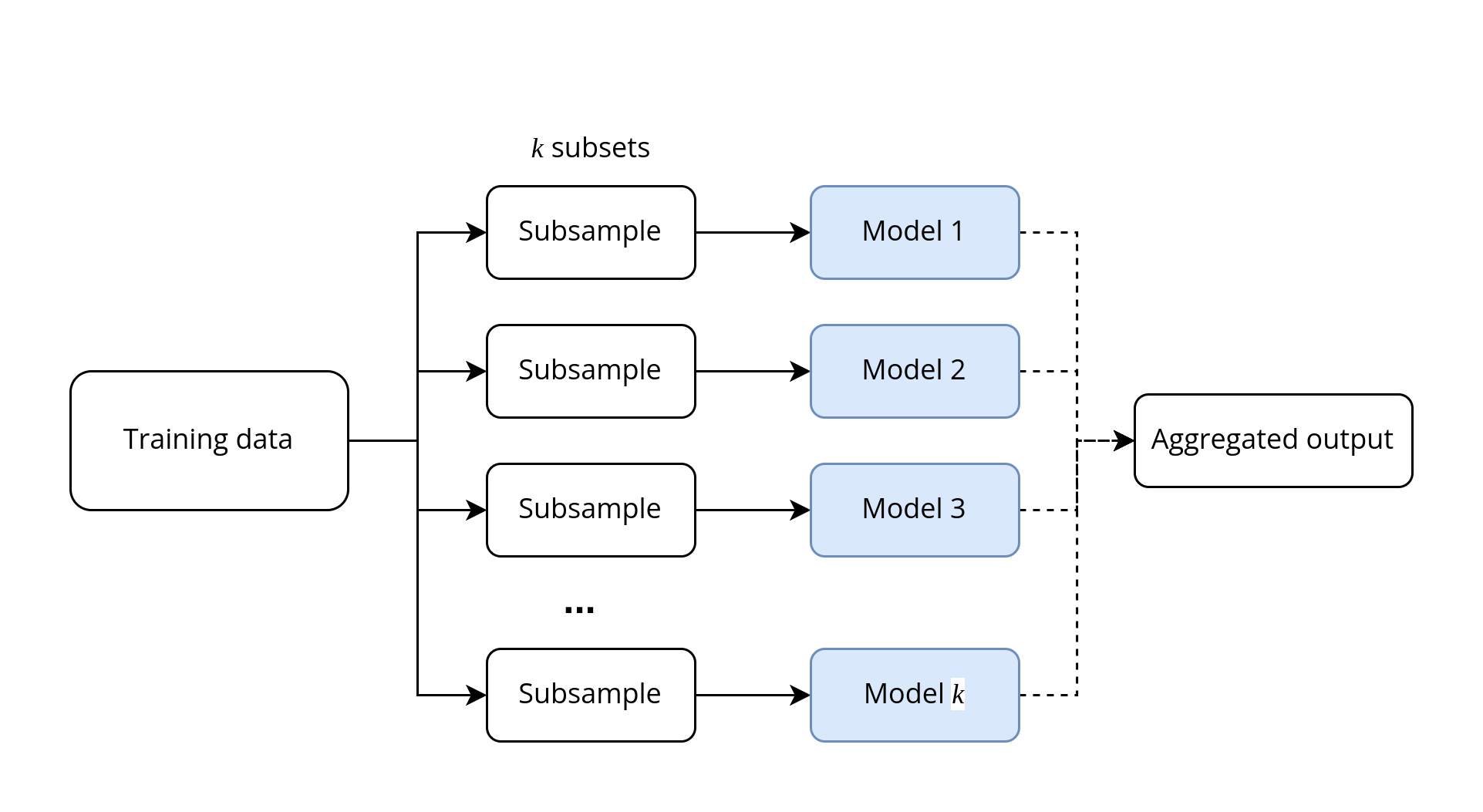
A very popular example of bagging is random forest.
You can very easily create a Radom forest in Scikit-Learn as:
from sklearn.ensemble import RandomForestRegressor
# Create the model with 50 trees
RF_model = RandomForestRegressor(n_estimators=50,
max_features='sqrt',
n_jobs=-1, verbose=1)
# and fit the training data
RF_model.fit(X_train, Y_train)To perform pasting just set bootstrap=False for RandomForestRegressor/ BaggingClassifier.
from sklearn.ensemble import BaggingClassifier
# Create the ensemble with 50 base estimators
Bc_model = BaggingClassifier(n_estimators=50,
max_samples=100,
bootstrap=False
n_jobs=-1, verbose=1)
# and fit the training data
bg_model.fit(X_train, Y_train)BaggingClassifier automatically performs soft voting if the base classifier can estimate class probabilities, i.e, it has predict_proba() methodBoosting
Boosting refers to any Ensemble method that can combine several weak learners to produce strong learners with more capacity than the individual models.
Boosting iteratively improves upon a sequence of weak learners training them sequentially, each trying to correct its predecessor.
Boosting works because at each next iteration, the model is punished to predict according to the residuals of the previous iteration.
The most popular boosting methods are AdaBoost (short for Adaptive Boosting) and Gradient Boosting.
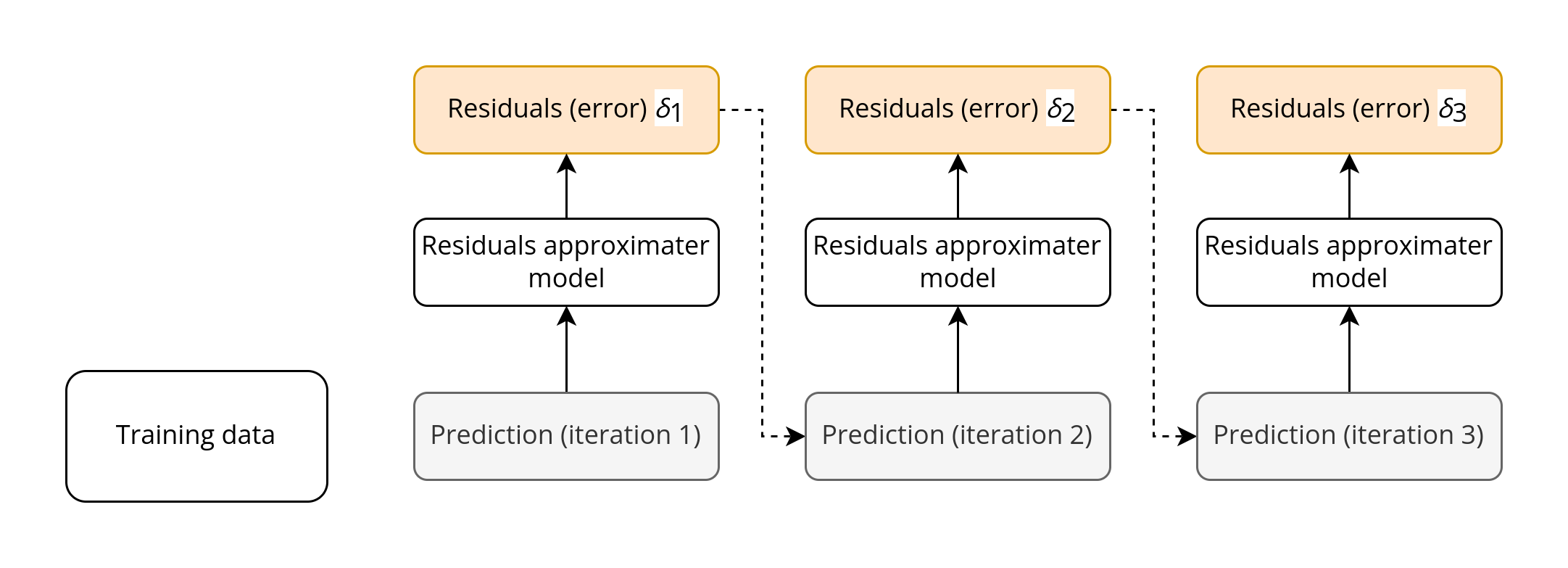
Once again, in scikit-learn we can implement it as follows:
from sklearn.ensemble import GradientBoostingRegressor
GB_model = GradientBoostingRegressor(n_estimators=1,
max_depth=1,
learning_rate=1,
criterion='mse')
# fit on training data
GB_model.fit(X_train, Y_train)One important drawback of this sequential learning technique is that it cannot be parallelized. As a result, it does not scale as well as bagging or pasting.
Stacking
Stacking can be thought of as an extension of simple model averaging of k models trained on complete dataset but with different types/algorithms. More generally, we could modify the averaging step to take a weighted average of all outputs.
Stacking comprises of two steps:
- Initially, initial models (typically of different types) are trained to completion on the full training dataset.
- In the second step, a meta-model is trained using the initial model outputs as features whose task is to best combine the outcomes of initial models to decrease the training error. Again it can be any machine learning model.
Stacking works because it combines the best of both bagging and boosting.
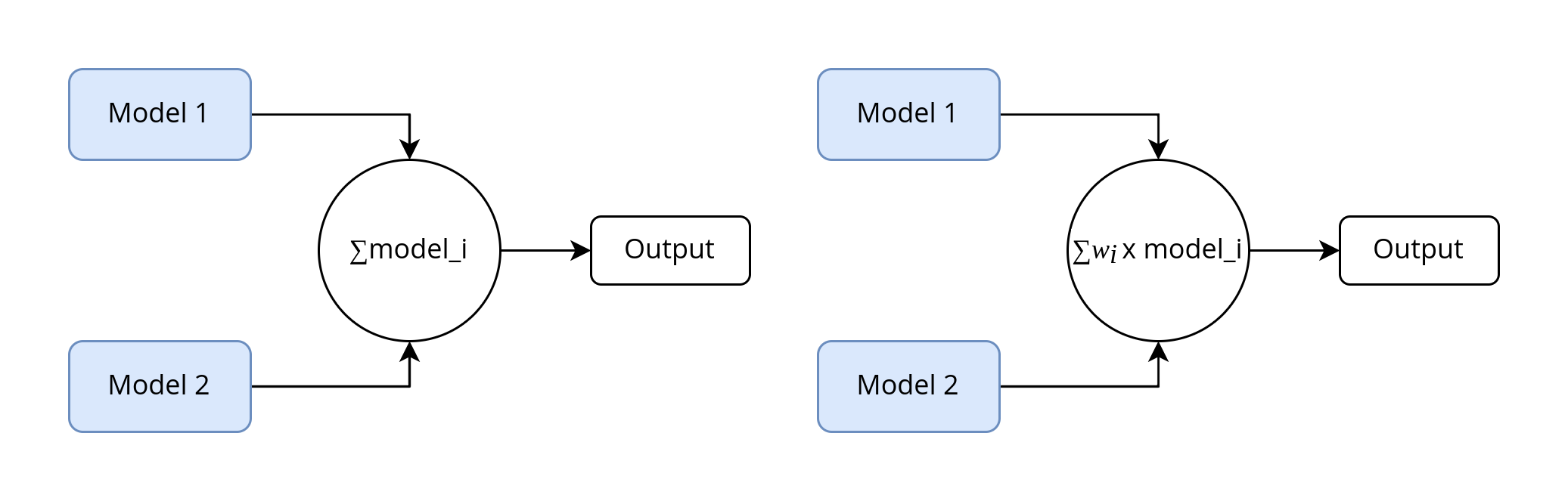
Trade-Offs and Alternatives
Increased training and design time
The obvious downtime to ensemble learning is increased training and design time. In ensemble design patterns, the complexity increases since instead of developing one single model, we are trying to model k-model, or maybe of different types if we are using Stacking.
However, we should carefully consider the overhead of building such ensemble models is worth it by comparing its accuracy and resource usage with simpler models.
Dropout as bagging
Dropout is a very popular regularization technique in Neural networks where a neuron is "dropped" during an interation based on its dropout-probability during training. It can be considered as an approximation of bagging, as a bagged ensemble of exponentially many neural networks.
Although, it's not exactly the same concept.
- In the case of bagging, the models are independent, while in the case of dropout, the parameters are shared.
- In bagging, the models are trained to convergence on their resepective training set, while with dropout, the ensemble member model will only be trained for a single step.
Decreased model interpretability
For many production ML tasks model interpretability and explainability is important. Ensembles doesn't fullfill this requirement.
Choosing the right tool for the problem
It's also important to keep the problem we were trying to solve in the first place. So, it's important to keep in mind the bias-variance trade-off and select the right tool for your problem. Bagging if you want to reduce variance, Boosting to reduce bias otherwise Stacking.
Hope you learned something new.
This is Anurag Dhadse, signing off.





