Up until now you might have only trained a single model, accepting a single or few inputs and probably deployed it so it send back the output sequentially as the model service serve each request sequentially.
Now, Imagine a scenario, you have a file with millions of inputs and then the service needs to responds with a file with millions of predictions. Ah, it's easy.
It isn't! Model deployment services poses scalability challenges. Often requiring the ML model servers to scale horizontally instead of vertically.
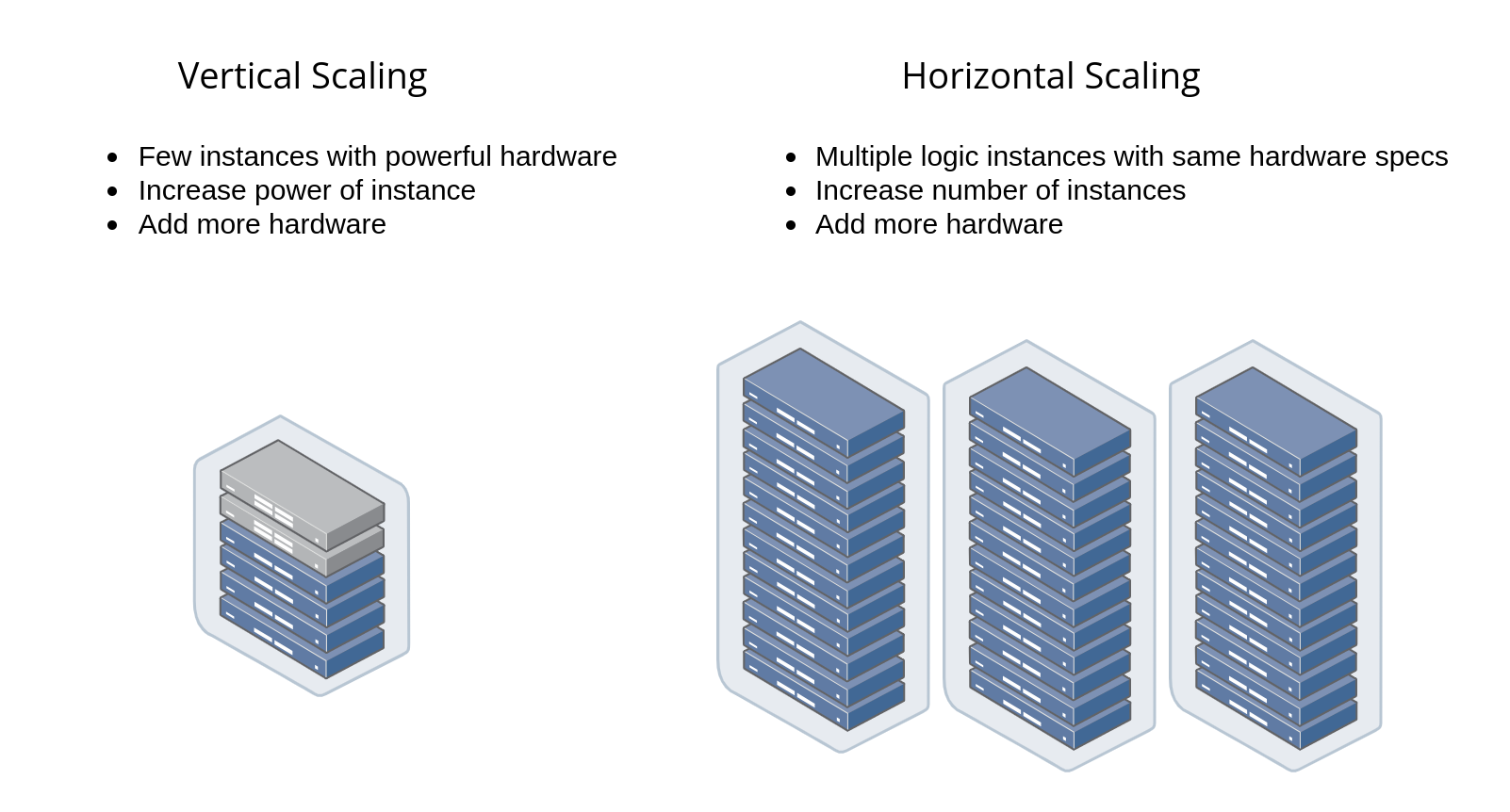
You might think that it should be obvious that the first output corresponds to the input instance and the second output to the second input instance. But for this to happen a server needs to process the full set of inputs serially; often requiring vertical scaling and becoming expensive to continue in the long run.
Instead, servers and hence ML models are deployed in large clusters (horizontally) and in the process they distribute the request to multiple machines, collect all resulting outputs and send them back. And hence horizontal scaling can be quite cheap. But in the process, you'll get jumbled output.
Server nodes that receive only a few requests will be able to keep up, but any server node that receives a particularly large array will start to fall behind. Therefore, many online serving systems will impose a limit on the number of instances that can be sent in one request.
So, How do we solve this problem?
Solution
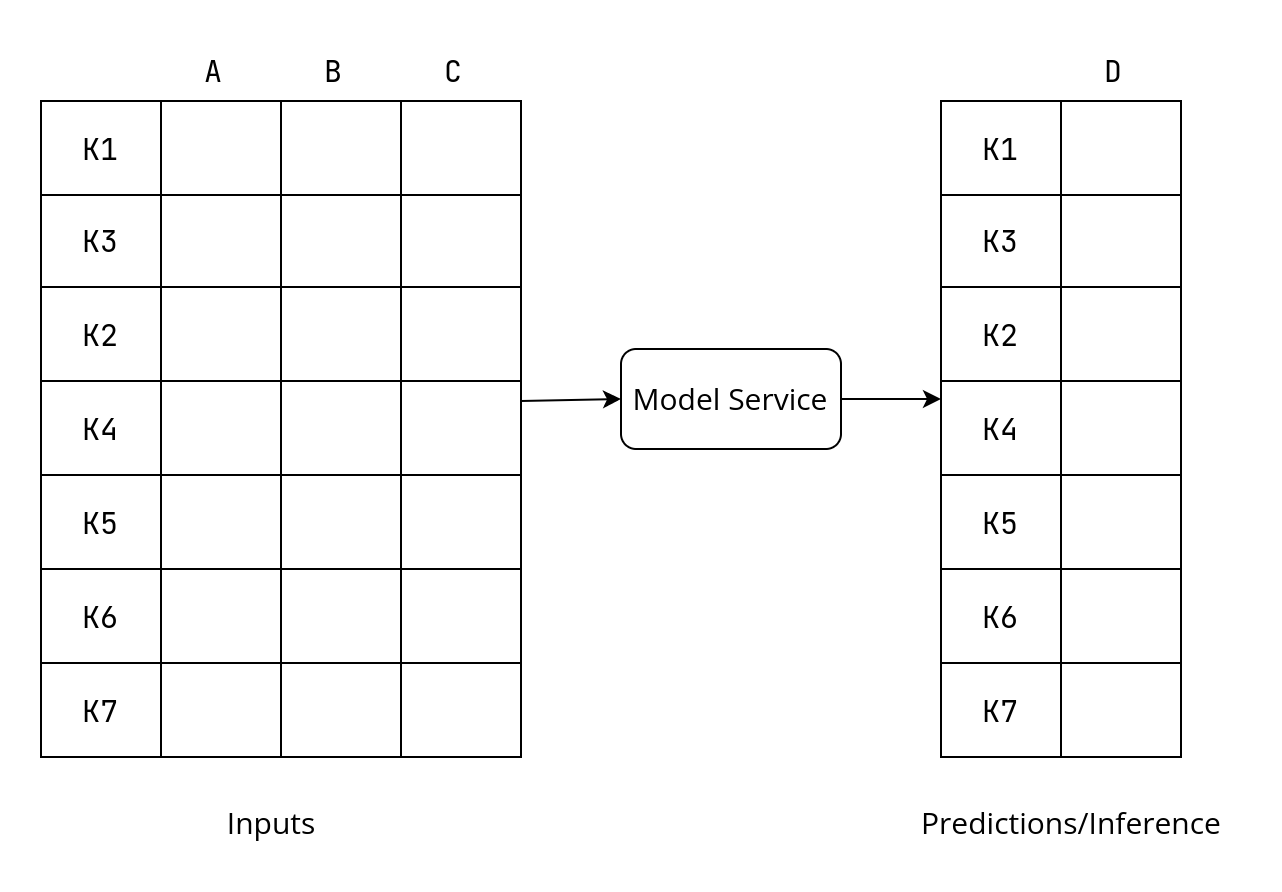
The solution is to use pass-through keys. Have the client supply a key associated with each input to identify each input instance. These keys will not be used as input to the model and hence called pass-through, not passing through the ML model.
Suppose, your model accepts inputs a, b, c to produce an output d. Then let the client also supply the key k along with the inputs as (k, a, b, c). The key can be as simple as an integer for a batch of requests or even UUID (Universally Unique Identifier) strings are great.
Here is how you pass through keys in Keras
To get your Keras model to pass through keys, supply a serving signature when exporting the model.
For example, in this code below the exported model would take four inputs (`is_male`, mother_Age, plurality, and gestation_weeks) and have it also take a key that it will pass through to the output along with the original output of the model (the babyweight):
# Serving function that passes through keys
@tf.function(input_signature=[{
'is_male': tf.TensorSpec([None,], dtype=tf.string, name='is_male'),
'mother_age': tf.TensorSpec([None,], dtype=tf.float32, name='mother_age'),
'plurality': tf.TensorSpec([None,], dtype=tf.string, name='plurality'),
'gestation_weeks': tf.TensorSpec([None,], dtype=tf.float32, name='gestation_weeks'),
'key': tf.TensorSpec([None,], dtype=tf.string, name='key')
}])
def keyed_prediction(inputs):
feats = inputs.copy()
key = feats.pop('key') # get the key out of inputs
output = model(feats) # invoke model
return {'key': key, 'babyweight': output}This model is then saved using the Keras model Saving API:
model.save(EXPORT_PATH,
signature={'serving_default': keyed_prediction})Adding keyed prediction capability to an existing model
To add a keyed prediction capability to the already saved model, just load the Keras model and attach a serving function and again save it.
While attaching our new keyed prediction serving function, do provide a serving function that replicated the older no-key behavior to maintain backward compatibility:
# Serving function that passes through keys
@tf.function(input_signature=[{
'is_male': tf.TensorSpec([None,], dtype=tf.string, name='is_male'),
'mother_age': tf.TensorSpec([None,], dtype=tf.float32, name='mother_age'),
'plurality': tf.TensorSpec([None,], dtype=tf.string, name='plurality'),
'gestation_weeks': tf.TensorSpec([None,], dtype=tf.float32, name='gestation_weeks'),
}])
def nokey_prediction(inputs):
output = model(feats) # invoke model
return {'babyweight': output}And then add our already defined keyed prediction serving function:
model.save(EXPORT_PATH,
signatures={'serving_default': nokey_prediction,
'keyed_prediction': keyed_prediction
})Trade-Offs and Alternatives
Why can't servers just assign keys to the inputs it receives? For online prediction, it is possible for servers to assign unique request IDs. For batch prediction, the problem is that the inputs need to be associated with the outputs, so the server assigning a unique ID is not enough since it can't be joined back to the input.
What the server needs to do is to assign keys to the inputs it receives before it invokes the model, uses the keys to order the outputs, and then remove the keys before sending along the outputs. The problem is that ordering is computationally expensive in distributed data processing.
Asynchronous Serving
Nowadays, many production ML models are Neural Networks and they involve matrix multiplication this can be significantly more efficient if done on Hardware Accelerator.
It is therefore more efficient to ensure that the matrices are within certain size ranges and/or multiples of a certain number. It can therefore, be helpful to accumulate requests (obviously up to a maximum latency) and handle the incoming requests in chunks. Since the chunks will consist of interleaved requests from multiple clients, the key, in this case, needs to have some sort of client identifier as well.
Continuous Evaluation
If you are doing continuous evaluation, it can be helpful to log metadata about the prediction requests so that you can monitor whether performance drops across the board or only in specific situations.
That's all for today. Hope you learned something new.
This is Anurag Dhadse, signing off.





